As a common practice, the fitting parameters of deep material network (DMN) are initiated randomly in the optimization process. Since the SGD algorithm converges to a band of local minima close to the “global minimum” , the structure of trained DMN strongly depends on the initial parameters. Meanwhile, the stochasticity of SGD in choosing the mini-batches also introduces uncertainty of the final structure at the early stage of training. With random initialization, the DMN databases trained for different RVEs are not analogous to each other in terms of the topological structure, so that a continuous migration between different database can not be realized through direct interpolation of the fitting parameters.
In this aspect, transfer learning of DMN is more advantageous as all the databases can be originated from the same pretrained database, and hence converge to similar network structures. With the DMN interpolation technique, we are able to generate a unified set of databases covering the full-range structure-property relationship. Another motivation of transfer learning is to improve the convergence of training by reusing the knowledge from pretrained networks.
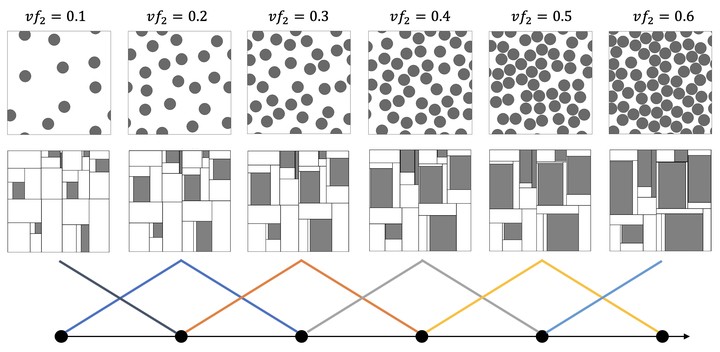
Since the databases created from transfer learning share the same base structure, intermediate databases can be generated by interpolating the fitting parameters. The unified databases show encouraging micromechanical results of predicting the volume fraction effect on elastic properties for 2D particle-reinforced composite.
The idea of database interpolation opens the possibility of incorporating multiple microstructural descriptors to derive a more general design map. From our perspective, it is promising to use the DMN framework with transfer learning and database integration in a broad class of materials design problems where reliable and efficient structure-property relationships are desired.